

Published
Updated
The first installment of my guide on how to set up Wagtail as a headless CMS for JavaScript frontends.
I gave a talk about this subject at Wagtail Space US 2022. You can find a recording of the event on YouTube.
Last year at RIPE NCC, we rewrote RIPE Labs using Wagtail, a CMS based on Django. It ended up being a monolithic application that spits out server side rendered HTML with Django templates.
This year we're revisiting Wagtail to rewrite our main site and I proposed decoupling backend and frontend, setting up a headless CMS paired with a JavaScript frontend framework.
The reason I proposed such a structure is to take advantage of React and a metaframework like Next.js or Gatsby. I'll mostly speak in terms of React because that's what I'm more familiar with, but we also evaluated Vue and what follows applies equally well.
To better understand how to set up such a project I went through The Definitive Guide to Next.js and Wagtail by Michael Yin and this boilerplate repo by Frojd. I recommend you checkout the repo first and get the book only if you need further explanations.
In this series of posts I'll show you how to set up a project with Wagtail as a headless CMS and Next.js on the frontend. I'll try my best to highlight the pain points, so you can come out with a honest evaluation of this setup. Here's a link to the companion repo that contains all the code from these posts.
If you're curious about our choice at RIPE NCC: we'll use Django templates this time too.
Why use a JavaScript framework?
First things first, why would I want to use a JavaScript framework instead of Django templates? There are good reasons for both approaches.
I think breaking down a UI into reusable components makes it easier to develop a consistent UI. Additionally encapsulated components are simpler to test individually and with the help of TypeScript you will catch errors, big and small, at build time that the Django templating engine will never catch.
When it comes to Django templates, I only know of Curlylint, but as of version 0.13 (the latest currently available), it's still to be considered experimental, and in my tests it did throw some false positives.
The flip side of JavaScript frameworks is that they increase complexity a little bit: Django templates work out of the box with all the other features of Django, such as sessions and authentication.
However, metaframeworks such as Next.js or Gatsby provide a great DX when developing frontends locally, much nicer than Django templates. More importantly their ability to pre-render pages and producing a static build is a perfect fit for a headless CMS. If you're interested in creating static builds without a JavaScript framework, you can look into wagtail-bakery.
Lastly, for teams that usually work with a well defined division between backend and frontend, Wagtail is a good choice.
Serving JSON from Wagtail
Ok, enough talk! What do you need to change in your Wagtail setup to make it fully headless?
Wagtail includes an optional module that exposes a public, read only, JSON-formatted API. However, it's not the most intuitive, in my opinion, and it still assumes you have HTML templates for all your pages.
By default, on the wagtail.core.Page model the method
responsible for rendering a page is
serve,
which returns a TemplateResponse as of Wagtail 2.16.1.
class Page(...): ... def serve(self, request, *args, **kwargs): #L1070 request.is_preview = getattr(request, "is_preview", False)
return TemplateResponse( request, self.get_template(request, *args, **kwargs), self.get_context(request, *args, **kwargs), )I suggest configuring Wagtail so that your frontend paths map 1:1
with the CMS. There are many ways of achieving this, such as
prepending calls to Wagtail with /api/ or using .json as a
suffix. You could also set up a different subdomain, such as
cms.example.com if your site lives at example.com.
After giving this some thought, I prefer having Wagtail on the same domain as my frontend and routing each request based on its Accept or Content-Type headers.
In the implementation below a request with header
Content-Type: application/json to /careers will receive a
JSON response, while a request that doesn't accept JSON will be
redirected to the rendered page.
In nginx we can route requests to the correct upstream server like this:
upstream frontend_upstream { server 127.0.0.1:3000;}upstream backend_upstream { server 127.0.0.1:8000;}
# redirect requests with content-type: application/json to Wagtailmap $http_content_type $get_upstream { default frontend_upstream; application/json backend_upstream;}
server { ... location / { ... proxy_pass http://$get_upstream$uri; }}And on our BasePage in Wagtail we can override the serve
method like this:
class BasePage(Page): class Meta: abstract = True
...
def serve(self, request, *args, **kwargs): """ If the request accepts JSON, returns an object with all the page's data. Otherwise it redirects to the rendered frontend. """ if request.content_type == "application/json": reponse = self.serialize_page() return JsonResponse(reponse) else: full_path = request.get_full_path() return HttpResponseRedirect( urllib.parse.urljoin(settings.BASE_URL, full_path) )Before this can work, you'll need to define custom serializers with Django REST framework. For the most part this is no big deal, as we will see in the last section, but for rich text some adjustments are needed.
Rendering Wagtail's rich text
Because Wagtail has a built-in module for a JSON API, you would
think you could re-use their serializer (you can for
StreamField!), but doing so will return the internal database
representation of rich text.
This can be a problem, because the representation of internal objects looks like this:
<!-- Link to another page --><a linktype="page" id="3">Contact us</a>
<!-- Embedded image --><embed embedtype="image" id="10" alt="A pied wagtail" format="left"/>The actual URL and images are only rendered when passing the
HTML through the |richtext template filter or through the
expand_db_html function from wagtail.core.rich_text.
So you'll want to override the get_api_representation method of
RichTextBlock in this way:
from wagtail.core.blocks import RichTextBlockfrom wagtail.core.rich_text import expand_db_html
class CustomRichTextBlock(RichTextBlock): def get_api_representation(self, value, context=None): return expand_db_html(value.source)Similarly for RichTextField, you'll want to use a custom field
serializer like so:
from rest_framework.fields import Fieldfrom wagtail.core.rich_text import expand_db_html
class CustomRichTextField(Field): def to_representation(self, value): return expand_db_html(value)Writing page serializers with Django REST framework
The last thing we need before we can spit out JSON is a serializer. What are serializers and what do they do?
Serializers allow complex data such as querysets and model instances to be converted to native Python datatypes that can then be easily rendered into JSON
Let's see it in action by creating a serializer for our abstract
BasePage. Because all our models will inherit from this class,
we can add common fields here so all pages will return the same
metadata.
from rest_framework import serializers
from .models import BasePage
class BasePageSerializer(serializers.ModelSerializer): class Meta: model = BasePage fields = ("id", "slug", "title", "url", "first_published_at")So far so good, serializing these fields is easy because they're strings, integers, and DateTime objects, which Django REST can handle automatically.
However, one of the main building blocks of Wagtail pages is the
StreamField and Django REST can't handle it out of the box, but
luckily Wagtail can. Let's update the serializer to handle
StreamField fields.
from rest_framework import serializers from wagtail.api.v2 import serializers as wagtail_serializers from wagtail.core import fields
from .models import BasePage
class BasePageSerializer(serializers.ModelSerializer): serializer_field_mapping = serializers.ModelSerializer.serializer_field_mapping.copy() serializer_field_mapping.update({ fields.StreamField: wagtail_serializers.StreamField, })
class Meta: model = BasePage fields = ( "id", "slug", "title", "search_description", "url", "first_published_at", )We now have all we need to create our first non-abstract model, which we'll be able to edit in the Wagtail interface as usual and fetch as JSON.
Putting it all together
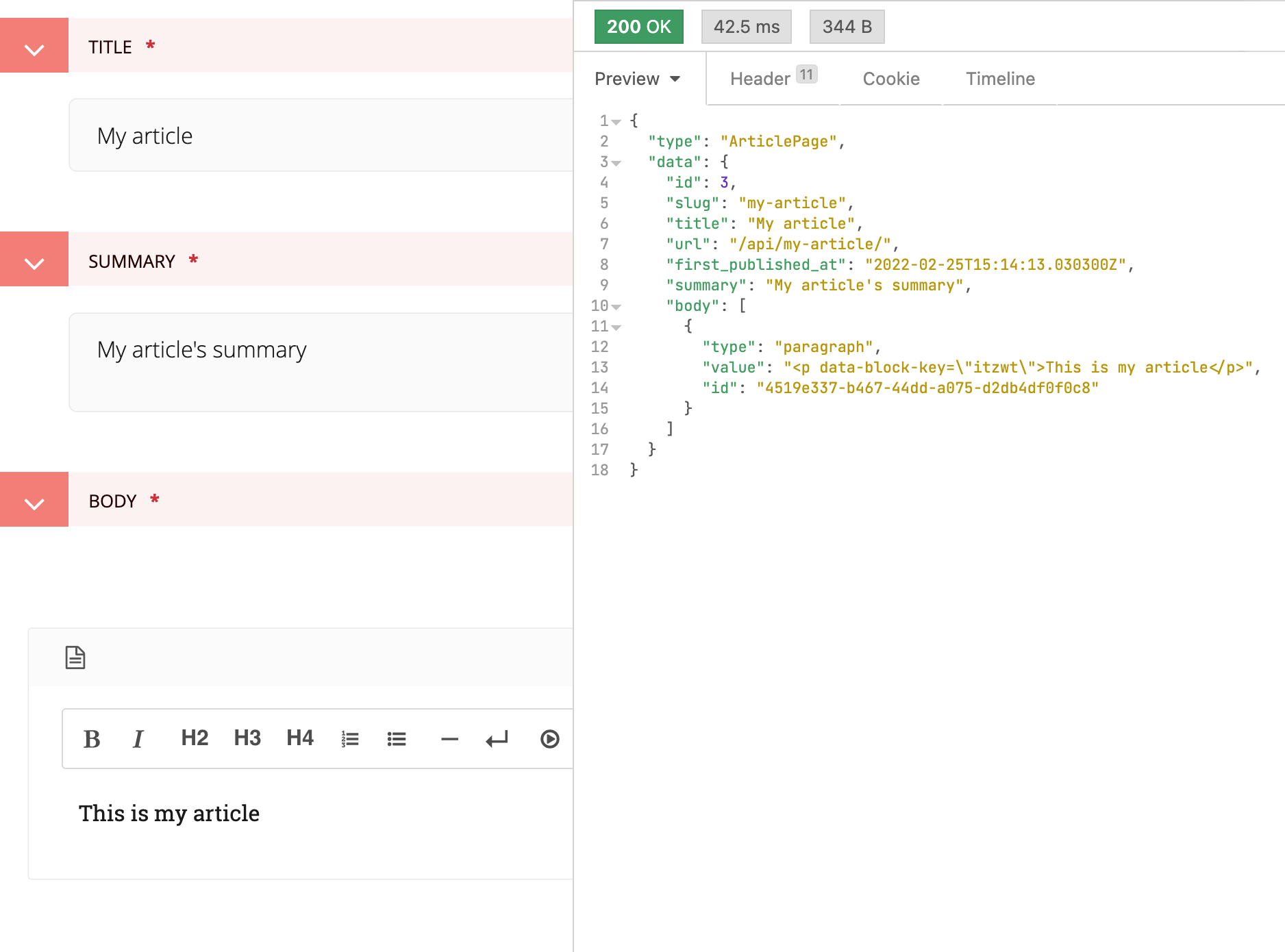
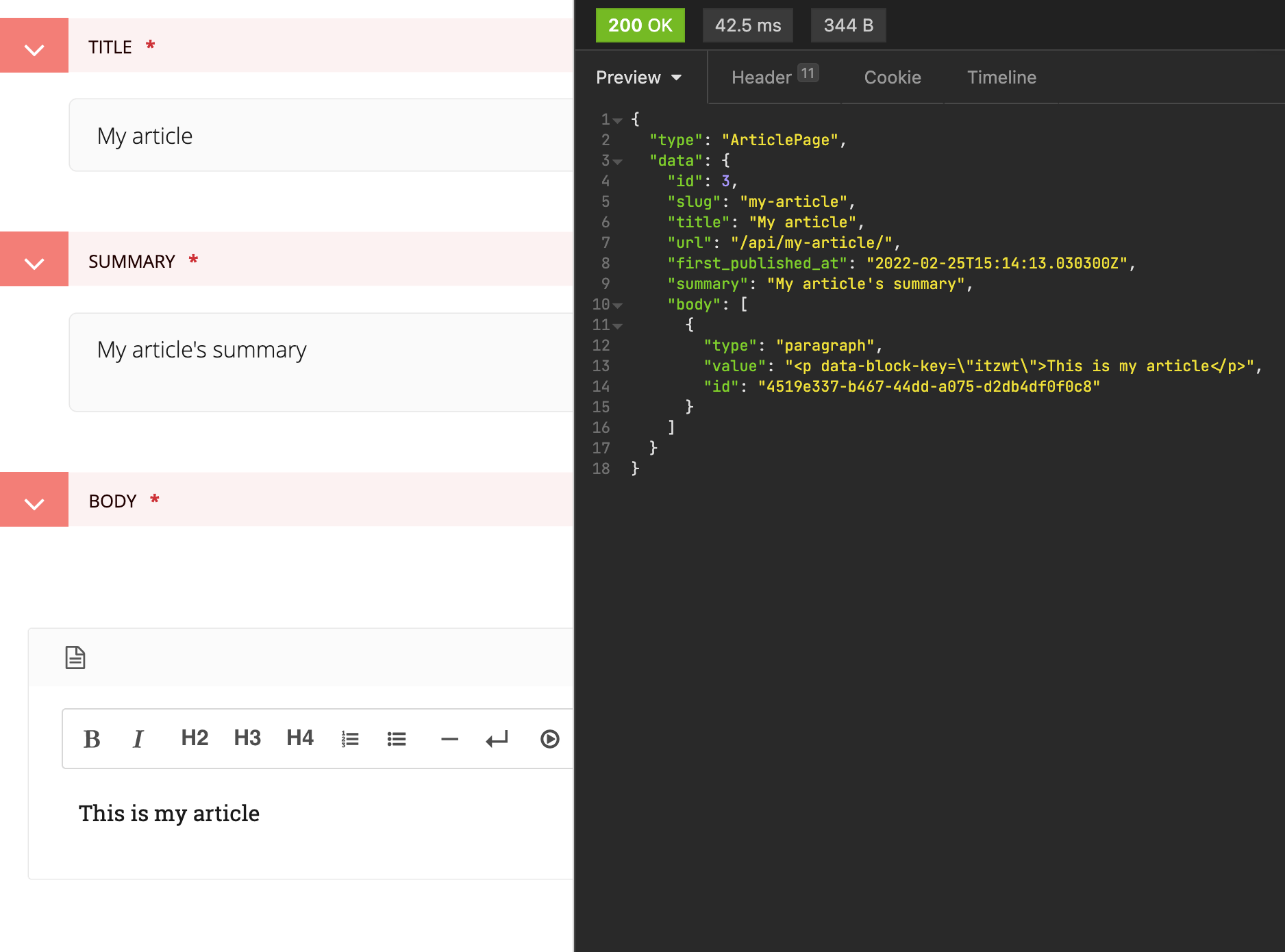
Screenshot of the Wagtail admin showing the creation of an
article and the JSON response from our custom
serve method
With all that said and done, let's create a Page model to add articles to our site. Our articles will be simple for now: they'll have a summary and a body with rich text and images.
from wagtail.core.fields import StreamFieldfrom wagtail.images.blocks import ImageChooserBlock
from .blocks import CustomRichTextBlock
...class ArticlePage(BasePage): body = StreamField( [ ("paragraph", CustomRichTextBlock()), ("image", ImageChooserBlock(icon="image")), ], )
content_panels = [ FieldPanel("title"), StreamFieldPanel("body"), ]Remember that each model we add needs its own serializer. Let's
add an ArticlePageSerializer then. Because the model inherits
from BasePage, we only need to extend the Meta.fields with
the body field on ArticlePage.
Since body is a StreamField, BasePageSerializer already
knows how to handle it.
from .models import ArticlePage...class ArticlePageSerializer(BasePageSerializer): class Meta: model = ArticlePage fields = BasePageSerializer.Meta.fields + ( "body", )If you try running this now, you'll get an error. We haven't
defined the serialize_page method on BasePage. We're going to
write it now, and it's the most important piece of the puzzle.
class BasePage(Page): ... serializer_class = None
def serialize_page(self): if not self.serializer_class: raise Exception( f"serializer_class is not set {self.__class__.__name__}", ) serializer_class = import_string(self.serializer_class) return { "type": self.__class__.__name__, "data": serializer_class(self).data, } ...
class ArticlePage(BasePage): serializer_class = "your_app.serializers.ArticlePageSerializer" ...There's a lot going on here, so let me break it down.
- We have added a
serializer_classproperty which isNoneby default as serializers don't work with abstract models. - We set the
serializer_classproperty onArticlePageto be the path to theArticlePageSerializerwe added earlier. - In
serialize_pagewe attempt to dynamically import the serializer and serialize the current object with it. - We return the name of the class as
"type", more on this in the next part of this guide.
The end result is that serialize_page will return a dictionary
along these lines:
{ "type": "ArticlePage", "data": { "id": 3, "slug": "my-article", "title": "My article", "url": "/api/my-article/", "first_published_at": "2022-02-25T15:14:13.030300Z", "search_description": "My article's summary", "body": [ { "type": "paragraph", "value": "<p data-block-key=\"itzwt\">This is my article</p>", "id": "4519e337-b467-44dd-a075-d2db4df0f0c8" } ] }}And BasePage.serve will return it in JSON form if we send a
request to /my-article.
Conclusion
This is the end of the first part of my guide about running Wagtail as a headless CMS. In this first part, we've seen how to transform the default behavior of Wagtail to return JSON instead of rendering templates.
In the next installment of this guide, we'll see in detail how to set up our frontend to consume this JSON API.